This information provides an overview of the EARTHSEQUENCING database structure, and how to provide new data for the DeepMIP effort.
...
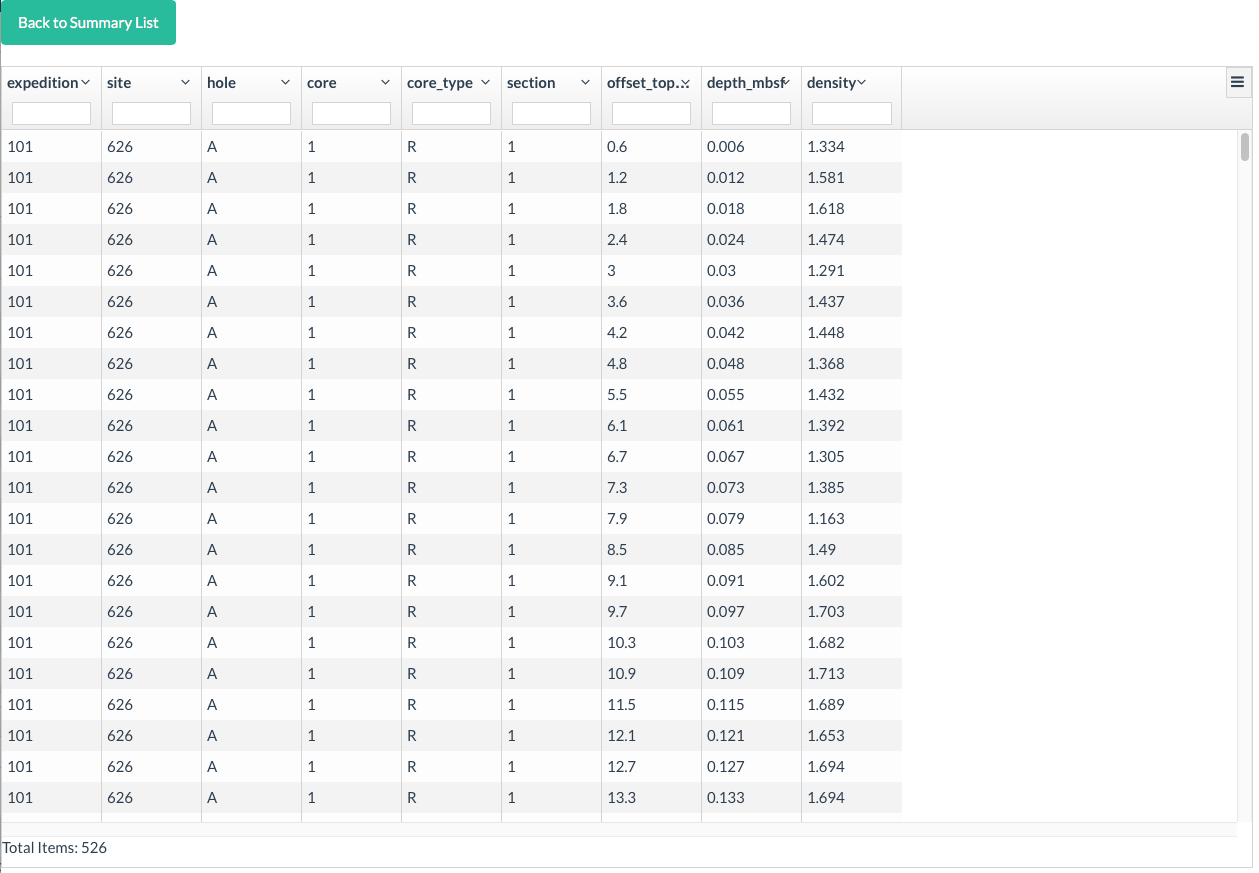
Below shows the initial demo page: you can filter by entering text in the empty fields, or sort.
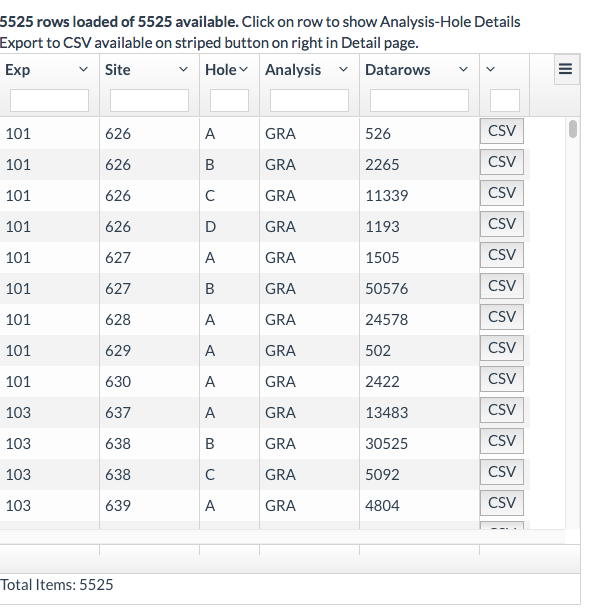
| Info |
|---|
There are two ways to export data: A click on the |


General instructions for preparing DeepMIP data for import into database
The database upload system maintains a number of internal conversion formats to massage the underlying CSV data into a structured format. This means ideally, the data files to be uploaded should follow a certain structure, and provide a minimal set of meta-data that describe the purpose and format for each column.
Example data files are provided below in tab separated format for actual data, and meta-data:
...
- Data files should be valid TSV (tab separated, preferred) or CSV (second choice) files. For floating point numbers, decimal point notation should follow EN format, i.e. a dot, not a comma (this often trips up with non-EN locales like in Germany, where a comma is used instead of a dot).
- For each datafile, the following meta-information should be supplied: Analysis type (e.g. GRA, MS, d18Obenthic, RSC etc), Hole (or land section, if so, provide WGS84 coordinates as lat lon), Author/Publication info, original download url where it exists, and publication doi in the form http://dx.doi.org/10.5194/gmd-2016-127.
- Data files MUST be organised per Hole (or unique land section) and SHOULD be per measurement-type (where possible).
- Each column SHOULD have a unique name. That means that e.g., multiple columns with a header called "Depth" should be made unique where possible. It is possible to override this on import but means extra work.
- Column header names should be all lower case, and not include spaces (can be replaced by "_" e.g.). Should be all ASCII (no things like ßÄ º etc).
- Each column entry should be formatted consistently in each file as you go down each column.
- Each column must relate to, and include, a specific sample identifier. For IODP, this includes for example Expedition, Site, Hole, Core, Core-type, Section, cm columns. In order to allow later calculations, this is crucial. Please split these identifiers into separate columns, as shown in the example above. Thus please not 342-U1408A-13H in one column.
- Date/Time columns (e.g. for timestamps) are always difficult to import. It would help to put dates/times into the following format: "1998-09-02T14:19:00.000+0000", i.e. 4 digit year, two digits month and day, letter T, HH:mm:ss with optional fractional milliseconds followed by the time zone (+0000 for GMT). A description of date formats if you want to provide your own is given here, and the example given would correspond to "yyyy-MM-dd'T'HH:mm:ss.SSSZ".
- To allow me to write proper import mappings, the following meta information also needs to be provided for each column. I think it would be best to put this into a separate CSV file with the same headers copied across, and then below the following rows
Datatype row that gives the type of data contained in each column, selecting the quoted text from
enum kNAM_Datatype : String {
case String = "string" // Any kind of text
case Double = "double" // A floating point number
case Datetime = "date" // A DateTime stamp like 1998-09-02T14:19:00+0000
case Bool = "bool" // True or False, Yes or No etc.
case Int = "int" // An Integer number
case ArrayInt = "array<int>" // Array of Ints in one column ... special use
case ArrayDouble = "array<double>" // Array of Doubles in one column ... special use
case ArrayString = "array<string>" // Array of Strings in one column ... special use
}
Semantic data meaning row, which lets the system know what kind of data is contained in each column. Exp, Site, Hole etc would be "sampleID", instrument calibration data could be "meta", specific identifiers exist for cm offset ("offset_top"), and typical IODP "depth_mbsf" and "depth_mcd" columns. It would be nice to include these for now where they exist, but these will later be computed on the fly. "value" is a generic measurement value, and if a file contains multiple measurement columns, one or several can be designated as either "value" or "value_main" or "value error", where "value_main" is the primary data type (e.g. for GRAPE: density would be "value_main", counts per second would be value). "valueerror" is for columns that provide error estimates. "-" means do not import this column into the database. "comment" is a generic comment column. Special instrument information (which device) can be marked by "instrument" or "instrument_group" but is probably only useful for IODP MST track data.
enum kNAM_ImportType : String {
case SampleID = "sampleID"
case Meta = "meta"
case OffsetTop = "offset_top"
case Depth_mbsf = "depth_mbsf"
case Depth_mcd = "depth_mcd"
case Value = "value"
case ValueMain = "value_main"
case ValueError = "valueerror"
case DoNotImport = "-"
case Instrument = "instrument"
case InstrumentGroup = "instrument_group"
case Comment = "comment"
}
- Physical unit row that provides a string describing the measurement unit, ideally in SI units. This is currently for information only, and could consist of strings like "cm", "m", "1/second", "permil VPDB", "%", "instr. units", "cie_lab", "g cm^{-3}", "ppm" etc. Have a look at the database prototype for some examples
- Where possible, supporting age-model or splice-table information should be provided separately (also with appropriate publication or doi or url links).
In Depth DB structure:
| Attachments |
|---|
|
Related articles
| Content by Label | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| Page properties | ||
|---|---|---|
| ||
|
...